
前言
本文主要介绍Hive 的基础概念,以及Handoop的大体架构,组件依赖,对于大数据有个总体的认识
Hive 基础概念
官网:https://hive.apache.org/
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hive 数据仓库软件支持使用SQL读取、写入和管理分布存储中的大型数据集。结构可以映射到存储中的数据。提供了一个命令行工具和JDBC驱动程序来将用户连接到Hive。
Hive的 特点:
- Hive是一个构建于Hadoop顶层的数据仓库工具,可以查询和管理PB级别的分布式数据。
- 支持大规模数据存储、分析,具有良好的可扩展性
- 某种程度上可以看作是用户编程接口,本身不存储和处理数据。
- 依赖分布式文件系统HDFS存储数据。
- 依赖分布式并行计算模型MapReduce处理数据。
- 定义了简单的类似SQL 的查询语言——HiveQL。
- 用户可以通过编写的HiveQL语句运行MapReduce任务。
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上。
- 是一个可以提供有效、合理、直观组织和使用数据的分析工具。
Hive应用场景:
思考: Hive 其实不是一个数据库或者数据存储系统,而且是一个数据工具,主要是将SQL语句转化为MapReduce任务执行。
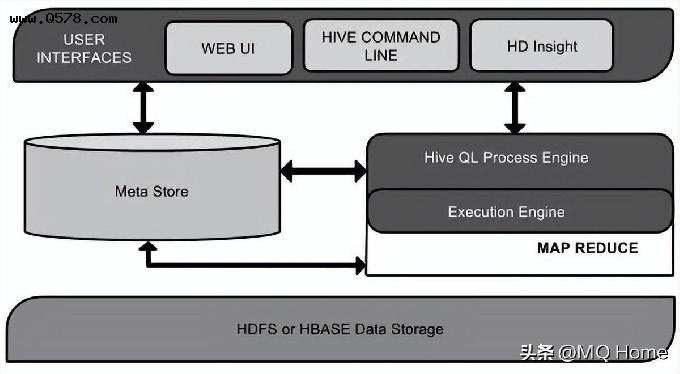
Hive 的结构
该组件图包含不同的单元。下表描述每个单元:
Hive的工作原理
下表定义Hive和Hadoop框架的交互方式:
Handoop 的结构
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口; (2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行; (3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态; (4)HBase是一个开源的,基于列存储模型的分布式数据库; (5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序; (6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
Handoop 集群部署
Handoop 组件依赖关系
Handoop的核心
参考资料:
https://blog.csdn.net/zl834205311/article/details/80334346
https://www.cnblogs.com/tieandxiao/p/8799287.html
https://www.yiibai.com/hive
https://www.jianshu.com/p/d68272609bf8
