
一、四种引用方式1.1 强引用1.2 软引用(SoftReference)1.3 弱引用(WeakReference)1.4 虚引用(PhantomReference)
二、如何判断对象是垃圾2.1 引用计数法2.2 根可达性分析
三、垃圾回收算法3.1 标记-清除(mark-sweep)3.2 标记-整理(mark-compact)3.3 标记-复制(mark-copy)
四、垃圾收集器4.1 分类及特点简述4.1.1 串行4.1.2 吞吐量优先4.1.3 响应时间优先4.2 串行垃圾回收器详述4.2.1 Serial4.2.2 Serial-Old4.2.3 流程图4.3 吞吐量优先垃圾回收器详述4.3.1 JVM相关参数4.3.2 流程图4.4、响应时间优先垃圾回收器详述4.4.1 JVM相关参数4.4.2 流程图4.3.3 CMS的特点
五、G1垃圾回收器5.1 相关JVM参数5.2 特点5.3 G1新生代垃圾回收5.4 G1老年代垃圾回收
一、四种引用方式
1.1 强引用
只有所有 GC Roots对象都不通过【强引用】引用该对象,该对象才可以被回收。
1.2 软引用(SoftReference)
- 仅有软引用引用该对象时,在垃圾回收后,若内存仍不足时再次发出的垃圾回收,回收软引用对象
- 可以配合引用队列来释放软引用自身
1.3 弱引用(WeakReference)
- 仅有弱引用引用该对象时,每次发生垃圾回收的时候,无论内存是否充足都会回收掉这部分对象
- 可以配合引用队列来释放软引用自身
1.4 虚引用(PhantomReference)
- 必须配合引用队列来使用,主要配合ByteBuffer的使用,被引用对象回收时,会将虚引用存入队列,由Reference Handler线程调用虚引用相关方法释放直接内存
二、如何判断对象是垃圾
2.1 引用计数法
某个对象只要有一处引用关系,该对象的引用次数就加1,如果一个对象的引用次数为0,则说明该对象是垃圾。
优势:实现简单,效率较高
弊端:如果有一对对象之间形成了相互引用,但是这两个对象都已经没有被其它对象所引用了,正常情况下,这一对对象应该被作为垃圾回收掉,但是因为形成了相互引用导致无法被回收。
2.2 根可达性分析
通过GC Root对象开始向下寻找,寻找不到的对象即说明没有被引用,那么这些没有被引用的对象被认定为垃圾。
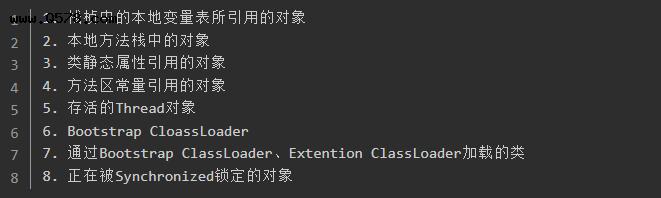
目前,如下对象可以作为GC Root对象:
三、垃圾回收算法
根据前面的描述,知道了哪些对象是垃圾需要被回收,那么回收是按照什么样的算法呢?
3.1 标记-清除(mark-sweep)
很好理解,即在GC的放生时候,先对所有对象进行根可达性分析,借此标记所有的垃圾对象;所有对象标记完毕之后会进行清理操作。
因此,总体来说,就是先标记再清除。
弊端;标记清除之后会产生大量不连续的内存碎片,碎片太多可能会导致程序运行过程中需要分配较大对象时,无法满足分配要求导致GC操作。
3.2 标记-整理(mark-compact)
该回收算法操作过程基本等同于标记-清除算法只不过,第二步有点区别,该种方式会在清除的过程中进行整理操作,这是最大的不同。
优势:最终不会出现若干空间碎片而导致的空间浪费。
弊端:在整理过程中带来的计算不可小觑。
3.3 标记-复制(mark-copy)
该种方式与前两种有较大的区别:
该种方式会将存储区分成两个部分,分别为From、To,其中From区域中可能存在着对象,而To区域始终为空,用做下一次接受数据做准备。
分别有两个指针指向这两个区域:From-Pointer、To-Pointer,
优点:这种算法非常适合早生夕死的对象
缺点:始终有一块内存区域是未使用的,造成空间的浪费。
四、垃圾收集器
垃圾收集器,就是实现了上述三种垃圾回收算法的具体实现
在Java中不同的“代”所保存的对象特点都不一样,因此Java在垃圾回收的选择上并没有偏爱一种,只采用一种算法方式,而是根据不同“代”对象的特点,采取不同的垃圾回收器(垃圾回收算法)。
4.1 分类及特点简述
4.1 串行
特点:
- 单线程
- 堆内存小,适合于个人电脑
4.2 吞吐量优先
特点:
- 多线程
- 堆内存较大,适合多核CPU
- 让单位时间内,STW的时间最短,即一段时间中,垃圾回收的时间与总运行时间的占比,占比越小越好,说明大多数时间都在处代码逻辑
4.3 响应时间优先
特点:
- 多线程
- 堆内存较大,适合多核CPU
- 尽可能让单次STW时间最短,只是单单的追求每次垃圾回收时间短即可,并不在意一段时间内发生了多少次垃圾回收。
4.2 串行垃圾回收器详述
JVM开关:-XX:+UseSerialGC = Serial + SerialOld
4.2.1 Serial
- 工作在新生代
- 采用复制算法
- 单线程
4.2.2 Serial-Old
- 老年代
- 采用标记-整理算法
- 单线程
4.2.3 流程图
4.3 吞吐量优先垃圾回收器详述
JDK1.8默认开启的,使用的算法本身与Serial是一致的,只是处理线程不一样而已。
4.3.1 JVM相关参数
- -XX+UseParallelGC
- 工作在新生代
- 复制算法
- -XX+UseParallelOldGC
- 工作在老年代
- 标记-整理算法
- -XX:+UseAdaptiveSizePolicy
- 动态调整Eden与Survivor的比例
- -XX:GCTimeRatio=ratio(默认为99)
- 占比 = 1/(1+radio)
- 表示希望在当前运行总时间中,GC的时间与总时间的占比小于等于上面的公式值。
- -XX:MaxGCPauseMills=ms(默认200ms)
- 单次垃圾回收的时间
- -XX:ParallelGCThread=n
- 指定并行的垃圾处理线程数,默认为CPU核数
- 因此在垃圾回收的过程中可能会导致CPU一下子跑满
4.3.2 流程图
4.4、响应时间优先垃圾回收器详述
4.4.1 JVM相关参数
- -XX:+UseParNewGC
- 工作在新生代
- -XX:+UseConcMarkSweepGC
- 工作在老年代,若垃圾回收失败时,则会退回到SerialOld垃圾回收。
- 采用标记清除算法;
- 可以并发执行,即在某些垃圾回收阶段,垃圾回收线程可以与用户线程一起执行。
- -XX:ConGCThread=n
- 指定在并发收集的过程中,可以使用n个线程处理垃圾回收
- -XX:CMSInitiationOccupancyFraction=precent
- 在下面的分析中,会介绍到浮动垃圾的概念,因此为了更加及时的清除浮浮动垃圾,在老年代的空间占用达到了Precent的时候,就会触发老年代的垃圾回收。
- -XX:+CMSScavengeBeforeRemark
- 因为老年代的CMS涉及到重新标记,重新标记就是在判断得到的垃圾对象是否又被重新引用。那么CMS会从新生代开始,使用根可达性分析(因为根可达性分析是不可逆的,也就是说无法通过某个对象直接查看其是否被引用,就好像二叉查找树一样,必须先从根对象开始往下寻找,看是否能找到该对象),而新生代中的对象较多,一个一个的从新生代对象进行更可达性分析,势必会拖慢响应分析,因此在重新标记之前,若改参数开关已打开,会先进行一次新生代的垃圾回收。
- -XX:ParallelGCThreads=n
- 指定并行的垃圾处理线程数,默认为CPU核数。
4.4.2 流程图
上图是:CMS垃圾回收器在老年代GC的工作流程图:
4.3.3 CMS的特点
五、G1垃圾回收器
5.1 相关JVM参数
- -XX:UseG1GC
- 开启使用G1垃圾回收器
- -XX:G1HeapRegionSize=n(默认是2048)
- 指定整个堆被划分成N个Region,因此每个Region的大小为堆空间 / N,但是有一条硬性规定,即每个Region的大小必须是 2 的整数倍。
- 两个初始Region数公式:
- 新生代的Region个数 = 5% * N
- 老年代的Region个数 = 95% * N
- 而对于新生代而言,在以往,新生代中进一步被划分为Eden区、Survivor(From、To)区,且三者的比值依然为:8:1:1,这样的划分在G1中同样的适用,只不过这样的划分不会出现在同一个Region中,而是Eden在某个独立的新生代Region中,From、To都各占一个独立的Region。
- -XX:InitaingHeapOccupancyPercent=45%
- 老年代的Region个数达到n%,即会触发老年代垃圾回收。
- –XX:G1MixedGCuntTarget=n
- 在混合模式下的垃圾回收,在并发清理阶段分为n次进行
- -XX:MaxGCPauseMillis=ms
- 指定的垃圾回收最长时间,如果时间很短,G1就只会回收那些回收价值最高的Region,这是为了能够达到这个暂停目标。
5.1 特点
- 全年代垃圾回收器
- G1负责全年代的垃圾回收,不像前面几种垃圾回收器,如:Serial(新生代)需要配合SerialOld(老年代)、CMS(老年代)需要配合ParNew(新生代)
- G1对堆的划分方式不一样
- 在G1之前,堆空间被“切”成两份,分别是:新生代、老年代,
- 而G1并没有按照传统方式去划分,G1将整个堆空间划分为一个一个相同大小的Region,而每个Region要么属于新生代,要么属于老年代,而每个新生代或老年代的Region在物理上不是一块连续的物理地址。而每个Region也不一定在整个项目周期中完全属于新生代或老年代而是处于一种动态变化的过程中。
- 每次回收某个代并不会全部进行扫描回收
- 回收价值:这是每个Region中带有的属性,Calc(对象的存活率、回收预计耗时、回收效果…)
- 而当进行回收时,会优先选取回收价值高的Region,从而减少垃圾回收的区域。
- 大对象存储
- 在以往分代模型中,当某个大对象进入内存时,如果整个新生代在垃圾清理之后依然无法使用,但是老年代却有足够的空间,此时该大对象会直接进入到老年代;
- 而在G1中并没有使用上述的方式存储过大的对象,而是大对象会被安排到了一个叫Humongous的Region中,在发生新生代或者老年代垃圾回收时,都会顺带清理Humongous的Region。
5.2 G1新生代垃圾回收
经过上面的文字分析,新生代的Region个数为所有Region个数的5%;这个数值其实是很小的,那么当新生代Region不够用的时候,JVM会划分更多的Region个数给新生代;
当新生代的Region个数占比所有Region个数超过 60%时,就会进行一次新生代的垃圾回收。
新生代垃圾回收会造成STW。
具体的垃圾回收算法同其它几个新生代垃圾回收器一样,新生代都使用复制算法。
5.3 G1老年代垃圾回收
老年代垃圾回收触发机制与参数-XX:InitaingHeapOccupancyPercent有关。
但是需要注意的是:这一次的老年代回收,其实是一次混合垃圾回收,会同时清理新生代、老年代、Humongous。
与新生代回收算法一致,依然使用复制算法,但是垃圾回收的过程等同于老年代响应时间优先的CMS方式
流程分为:
