
从内存分配开始
在上一篇的流程图中,我们看到最后的流程中,在_class_createInstanceFromZone,我们分为三步:
- 1、size = cls->instanceSize(extraBytes);获取对象需要分配的内存大小
- 2、obj = (id)calloc(1, size);如何申请内存
- 3、obj->initInstanceIsa(cls, hasCxxDtor);初始化isa
这一篇我们来分析获取需要分配的大小,以及具体如何分配内存,也就是我们的第1步和第2步。
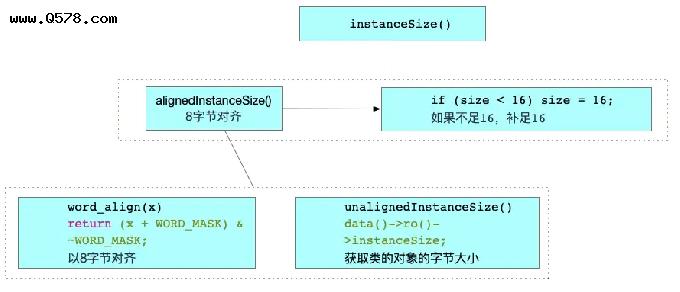
分析instanceSize函数的实现
size_t instanceSize(size_t extraBytes) const { if (fastpath(cache.hasFastInstanceSize(extraBytes))) { return cache.fastInstanceSize(extraBytes); } size_t size = alignedInstanceSize() + extraBytes; // CF requires all objects be at least 16 bytes. if (size < 16) size = 16; return size;}
我们从alignedInstanceSize开始看,这个方法中
uint32_t alignedInstanceSize() const { return word_align(unalignedInstanceSize());}
这个方法中的unalignedInstanceSize我们再来看看
uint32_t unalignedInstanceSize() const { ASSERT(isRealized()); return data()->ro()->instanceSize;}
我们来分析data()->ro()->instanceSize,data()实现为:
class_rw_t *data() const { return bits.data();}
class_ro_t是类在编译器存储类信息的数据结构,它里面包含了类的实例变量、方法列表、协议列表等,class_rw_t是用来存储 在dyld的_map_images方法中将分类的各种信息与class_ro_t合并后的信息。
data()->ro()->instanceSize也就是获取对象所有实例变量需要的存储大小。
我们再看word_align的实现
# define WORD_MASK 7ULstatic inline uint32_t word_align(uint32_t x) { return (x + WORD_MASK) & ~WORD_MASK;}
这个方法先将大小加上7,然后和~WORD_MASK进行逻辑与,由于7的二进制为0000 1111,对它取反后1111 0000,再与前面进行与,那么我们的内存分配的大小就是8的倍数了,也就是8字节对齐
最后,if (size < 16) size = 16;这一步就是如果不足16字节,那么我们就补足16,所以一个OC对象,至少是16个字节。
整个步骤流程如下:
instanceSize流程
获取内存大小的三种方式
我们在OC中获取内存大小的三种方式分别是:
- sizeof操作符 获取数据的类型占用空间的大小
- class_getInstanceSize(Class _Nullable cls) 获取实例对象中成员变量所需要占用的内存大小
- malloc_size(const void *ptr) 获取系统实际分配的内存大小
我们创建一个LWTestClass来测试
@interface LWTestClass : NSObject@property (nonatomic, copy) NSString *name;@property (nonatomic, copy) NSString *nickName;@property (nonatomic, assign) int age;@property (nonatomic, assign) long height;@endint main(int argc, const char * argv[]) { @autoreleasepool { LWTestClass *person = [LWTestClass alloc]; person.name = @”Cooci”; person.nickName = @”KC”; NSLog(@”%@ – %lu – %lu – %lu”,person,sizeof([LWTestClass class]),class_getInstanceSize([LWTestClass class]),malloc_size((__bridge const void *)(person))); } return 0;}打印结果: – 8 – 40 – 48
如上面的结果
- sizeof中是[LWTestClass class],它是一个指针,我们指针值是8,所以是8
- class_getInstanceSize中获取的是LWTestClass类的对象中实例变量所需的大小,我们来分析LWTestClass类结构,isa占8字节,name8字节,nickName8字节,age4字节补齐到8字节,height8字节,所以LWTestClass类只用40字节就可以保证存储了。
- malloc_size显示系统分配的内存为48字节,为什么是48字节呢?我们之前不是看到类的字节对齐不是8吗?40也是8的倍数,为什么不是分配40字节呢?
为什么是48字节?
我们在开篇中所说的第一步是获取对象所需空间大小,这里我们只能确定对象内存的内存布局是8字节对齐,这也是class_getInstanceSize获取到的内存大小,malloc_size获取到的是系统分配的内存大小,这是属于我们第二步中obj = (id)calloc(1, size);的内容,calloc方法的分析我们需要用libmalloc源码,具体的调用顺序我们不一一列举,大致的调用过程如以下流程图与核心代码。
calloc调用流程
#define SHIFT_NANO_QUANTUM 4#define NANO_REGIME_QUANTA_SIZE (1 SHIFT_NANO_QUANTUM; // round up and shift for number of quanta //再左移4位,这样得到的大小就是16的倍数 //内存分配也就是以16字节对齐了 slot_bytes = k << SHIFT_NANO_QUANTUM; // multiply by power of two quanta size *pKey = k – 1; // Zero-based! return slot_bytes;}
所以,在前面的例子中,我们计算出对象所需的内存字节大小为40,进行16字节对齐后,我们实际分配的内存大小为48.
为什么系统分配内存要以16字节对齐
这个没找到具体的答案,猜想如下:
- 一个对象是一个struct objc_object的结构体,它至少有一个成员变量isa,一个isa占的大小为8字节
- 如果我们以8字节来分配,两个连续的对象在内存中就是连续存储在一起的,如果我们以内存偏移(offset)来访问的话,如果有一定的错误,就会访问到另一个对象的isa中,这样会造成一定的不安全性。
这段有想法的大佬希望可以留言给予指导
内存对齐
上面我们说内存对齐,那么内存对齐有什么规则呢?为什么要内存对齐呢?
内存对齐规则
struct/class/union内存对齐原则有四个:
- 1).数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节, 则要从4的整数倍地址开始存储),基本类型不包括struct/class/uinon。
- 2).结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部”最宽基本类型成员“的整数倍地址开始存储.(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储.)。
- 3).收尾工作:结构体的总大小,也就是sizeof的结果,.必须是其内部最大成员的”最宽基本类型成员”的整数倍.不足的要补齐.(基本类型不包括struct/class/uinon)。
- 4).sizeof(union),以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
内存对齐实践
我们设置3个结构体,并分别打印它们所占字节大小
struct TestStruct1{ double a; int b; bool c; short d;}st1;struct TestStruct2{ int a; double b; bool c; short d;}st2;struct TestStruct3{ int a; double b; struct TestStruct1 st; bool c; short d;}st3;int main(int argc, const char * argv[]) { NSLog(@”st1:%lu,st2:%lu,st3:%lu”,sizeof(st1),sizeof(st2),sizeof(st3)); //打印结果:st1:16,st2:24,st3:40 return 0;}
从结果可以看到,st1和st2结构体中所含有的数据类型与个数相同,但位置不同,它们所占的大小也变得不一致了。
下面我们来分析它们分别的内存构成:
struct TestStruct1
- a占8字节,从0开始,它排在内存[0,7]的位置上
- b占4字节,从8开始,8是4的倍数,符合规则,所以b存在内存[8,11]位置上
- c占1字节,从12开始,12是1的倍数,符合规则,所以c存在内存12位置上
- d占2字节,从13开始,但是13不是2的倍数,所以往后到14的位置上,它是2的倍数,所以d存在内存[14,15]位置上
- 所有成员变量排在[0,15]位置上,它的总大小为16,是最大成员变量double(8字节)的倍数,所以struct TestStruct1的总大小为16字节
struct TestStruct2
- a占4字节,从0开始,它排在内存[0,3]的位置上
- b占8字节,从4开始,但是4不是8的倍数,所以往后顺排到8开始排,以b存在内存[8,15]位置上
- c占1字节,从16开始,16是1的倍数,符合规则,所以c存在内存16位置上
- d占2字节,从17开始,但是17不是2的倍数,所以往后到18的位置上,它是2的倍数,所以d存在内存[18,19]位置上
- 所有成员变量排在[0,19]位置上,它的总大小为20,不是最大成员变量double(8字节)的倍数,我们在后面补0凑够24变为8的倍数,所以struct TestStruct2的总大小为24字节
struct TestStruct3
- a占4字节,从0开始,它排在内存[0,3]的位置上
- b占8字节,从4开始,但是4不是8的倍数,所以往后顺排到8开始排,以b存在内存[8,15]位置上
- st是一个结构体变量,它占16字节,它内部最大的成员变量所占字节数为8,st从16开始,它是8的倍数,符合规则,所以st排在内存[16,31]的位置上
- c占1字节,从32开始,32是1的倍数,符合规则,所以c存在内存32位置上
- d占2字节,从33开始,但是33不是2的倍数,所以往后到34的位置上,它是2的倍数,所以d存在内存[34,35]位置上
- 所有成员变量排在[0,35]位置上,它的总大小为36,不是最大成员变量double和struct TestStruct1(8字节)的倍数,我们在后面补0凑够40变为8的倍数,所以struct TestStruct2的总大小为40字节
三个结构体的内部布局如下图
结构体内存构成
为什么要内存对齐
回答这个问题,我们要从内存、CPU以及平台三个方向来回答
1.平台
移植原因:不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2.CPU原因
- CPU位数就是CPU的数据总线宽度,而宽度决定了它的单次数据传送量,比如我们现在iOS平台一般都是64位,那么64位的CPU一次通电可以传输8个字节的数据,那么我们8个字节倍数的内存对齐,可以最大化的节省CPU传输的次数。
- 在CPU眼里,内存是一块一块的,块的大小可以是2、4、8、16字节大小,因此CPU在读取内存时是一块一块进行读取的,块大小称为memory access granulatity,我们将它翻译为内存读取粒度。
- 假设CPU要读取一个4字节的int类型数据到寄存器中,分两种情况讨论: 1)数据从0字节开始 2)数据从1字节开始
- 假设内存读取粒度为4
- 当从0字节开始时,CPU只需要读取一次即可把这4字节的数据完全读取到寄存器中
- 当该数据是从1字节开始时,问题变得比较复杂,此时该int类型数据不是位于内存读取边界上,那么CPU对它进行读取,要分为两次读取
- 此时CPU先访问一次内存,读取0-3字节的数据进寄存器,并再次读取4-5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1-4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了CPU性能。
- 另外,由于平台原因,有些CPU可能未到边界即已报异常。
3.内存原因
我们先讲讲内存结构
- 内存的物理构造中,一个内存是由若干个黑色内存颗粒构成的,每一个内存颗粒叫做一个chip
- 每一个chip内部,是由8个bank组成的
- 在每个bank内部,就是电容的行列矩阵结构。(注意,二维矩阵中的一个元素一般存储着8个bit,也就是说包含了8个小电容)
- 8个同位置的元素,一起组成在内存中连续的64个bit
- 通过内存的物理结构我们可以看出,内存中最小单位就是字节,操作系统在管理它的时候,最小单位也就是字节。另外,通过上述的我们还有一个额外发现。那就是在内存中连续的64个bit,其实在内存的物理结构中,并不连续。而是分散在同位置的8个rank上的。
- 内存在进行的时候,一次操作取的就是64bit,所以内存对齐最底层的原因是内存的IO以64bit为单位进行的。对于64位数据宽度的内存,假如cpu也是64位的cpu(现在的计算机基本都是这样的),每次内存IO获取数据都是从同行同列的8个chip中各自读取一个字节拼起来的。从内存的0地址开始,0-63bit的数据可以一次IO读取出来,64-127bit的数据也可以一次读取出来。CPU和内存IO的硬件限制导致没办法一次跨在两个数据宽度中间进行IO。
- 假如对于一个c的程序员,如果把一个bigint(64位)地址写到的0x0001开始,而不是0x0000开始,那么数据并没有存在同一行列地址上。因此cpu必须得让内存工作两次才能取到完整的数据。效率自然就很低。
- 如果不强制对地址进行操作,仅仅只是简单用c定义一个结构体,编译和链接器会自动替开发者对齐内存的。尽量帮你保证一个变量不跨列寻址。
- 在内存硬件层上,还有操作系统层。操作系统还管理了CPU的一级、二级、三级缓存。实际中不一定每次IO都从内存出,如果你的数据局部性足够好,那么很有可能只需要少量的内存IO,大部分都是更为高效的高速缓存IO。但是高速缓存和内存一样,也是要考虑对齐的。
作者:默默_David链接:https://www.jianshu.com/p/d285a33bf88f来源:简书著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
