
WAL 概述
WAL 是 write-ahead log 系统,其核心思想是将用户的所有修改操作(插入、删除)写入日志,然后再应用到系统状态。一旦日志写入成功,就可以通知用户操作成功。由于日志采用尾部追加方式写入,耗时较短,因此不会长时间阻塞用户线程。另外,为防止意外退出导致数据丢失,系统重启时会根据日志重做用户操作,保证数据可靠性。
WAL – 预写日志
WAL 一直是传统 RDBMS 系统中的一个共识,用于帮助保证原子性和持久性(ACID 的 A 和 D)。对表的所有更新首先写入 WA),然后异步的方式使用。
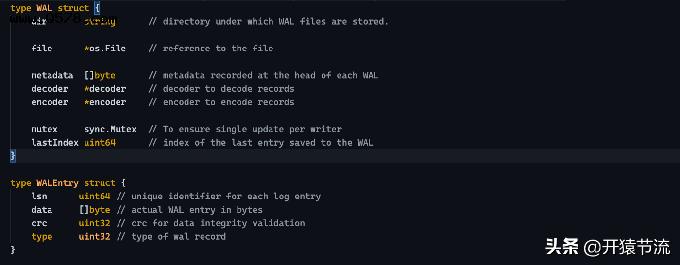
示例 WAL 和 WALEntry 结构:
type WAL struct { dir string // 存放 WAL 文件的目录。 file *os.File // 引用文件 metadata []byte // 每个 WAL 解码器头部记录的元数据 *decoder // 解码器解码记录 编码器 *encoder // 编码器编码记录 mutex sync.Mutex // To确保每个写入器一次更新 lastIndex uint64 // 保存到 WAL 的最后一个条目的索引} type WALEntry struct { lsn uint64 // 每个日志条目的唯一标识符 data []byte // 实际 WAL 条目(以字节为单位) crc uint32 // crc for数据完整性验证 type uint32 // wal 记录的类型 }
为什么需要 WAL
为什么不将更改直接刷新到实际数据文件?
它有2个方面——
WAL设计
WAL 是一个仅附加日志,它将数据存储中的每个状态更改存储为日志。
一个单独的异步进程可以从 WAL 读取操作,然后按照正常流程通过不同的缓存将数据更新应用于磁盘上的实际数据文件,有助于提高数据存储的写入吞吐量。
此外,如果发生故障,可能会有未应用的更新,由于我们在 WAL 文件中存在操作,我们可以从 WAL 重放操作并应用它们以使数据存储恢复到一致状态。因此,WAL 帮助我们确保数据的完整性和可靠性,同时仍然允许我们的数据存储具有高写入吞吐量。
注意事项
1. 将 WAL 操作刷新到磁盘
如前所述,对磁盘的写入可能不会直接刷新,考虑到写入系统中导致性能的问题,需要进行权衡刷新频率或微批处理或两者来将更改刷新到磁盘,以帮助提高性能。请注意,此处存在数据丢失的风险。
2. 损坏检测
需要确保任何刷新到磁盘的操作都不会损坏, WAL 记录还包含一个 CRC 值,该值可用于验证何时从 WAL 读取记录并确保没有损坏。
3. 重复操作
由于 WAL 是一个附加追尾的文件,因此如果客户端由于通信故障而重试,可能会遇到在 WAL 上写入重复操作的情况。因此,每当读取 WAL 时,要确保忽略重复项,或者对应用数据的动作具有幂等性的。
现状
1)所有数据库,包括像Cassandra这样的NoSQL数据库都使用WAL来保证持久性。
2) Kafka 使用了与 WAL(Commit Log) 类似的结构。
3) 像 Rocks DB、Level DB 这样的 KV 存储和像 Apache Ignite 这样的分布式缓存也使用 WAL。
概括
总而言之,WAL 提供一下价值
1) 更快的性能和吞吐量,避免了所有更改的数据刷新/磁盘写入。
2) 重启时的可恢复性,操作可以从 WAL 应用到实际的数据存储。
3)能够恢复到时间点快照,我们在 WAL 中存在所有操作。
