
通过kubeadm部署一个k8s集群
1 安装前准备
具体步骤参见 我的另一篇博文。Linux安装Docker、K8s(环境准备和Docker安装)
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供管理器的发行版提供通用的指令
- 每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
- 2 CPU 核或更多
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 开启机器上的某些端口。请参见这里 了解更多详细信息。
- 禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
- 确保每个节点上 MAC 地址和 product_uuid 唯一性你可以使用命令 ip link 或 ifconfig -a 获取网络接口的时间 MAC 地址可以使用 sudo cat /sys/class/dmi/id/product_uuid 命令对 product_uuid 校验一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装 失败。
- 检查网络适配器如果你有一个以上的网络适配器,同时你的 Kubernetes 组件通过默认路由不可达,我们建议你预先添加 IP 路由规则,这样 Kubernetes 集群就可以通过对应的适配器完成连接。
- 允许 iptables 检查桥接流量确保 br_netfilter 模块被加载。这一操作可以通过运行 lsmod | grep br_netfilter 来完成。若要显式加载该模块,可执行 sudo modprobe br_netfilter。为了让你的 Linux 节点上的 iptables 能够正确地查看桥接流量,你需要确保在你的 sysctl 配置中将 net.bridge.bridge-nf-call-iptables 设置为 1。例如
cat <<EOF | sudo tee /etc/modules-load.d/k8s.confbr_netfilterEOFcat <<EOF | sudo tee /etc/sysctl.d/k8s.confnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1EOFsudo sysctl –system
2 添加阿里云yum软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF[kubernetes]name=Kubernetesbaseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64enabled=1gpgcheck=0repo_gpgcheck=0gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgEOF
3 安装kubeadm和kubelet
版本号最好选择一个稳定版本,文档使用的是1.21.3
yum install -y kubelet-1.21.3 kubeadm-1.21.3systemctl enable kubelet
4 部署master节点
在Master节点上输入执行以下命令:
kubeadm init –apiserver-advertise-address=192.168.XXX.xxx –image-repository registry.aliyuncs.com/google_containers –kubernetes-version v1.21.3 –service-cidr=10.96.0.0/12 –pod-network-cidr=10.244.0.0/16 –ignore-preflight-errors=all
参数说明
- apiserver-advertise-address 集群通告地址
- image-repository 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
- kubernetes-version K8s版本,与上面安装的一致
- service-cidr 集群内部虚拟网络,Pod统一访问入口
- pod-network-cidr Pod网络,与下面部署的CNI网络组件yaml中保持一致
初始化完成后,最后会输出一个join命令,先记住,下面用。
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.Run “kubectl apply -f [podnetwork].yaml” with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.xxx.xxx:6443 –token 46ok5q.cnv0yj8p1arec3is –discovery-token-ca-cert-hash sha256:0cae5db1df5fc4796147583f25750faeec420bd82fb8cb7b2b4121d4d4a0066e
5.加入kubernetes node
在Node节点(示例中为192.168.xxx.xxx,192.168.xxx.xxx)上执行。
向集群添加新节点,执行之前记录的kubeadm join命令:
kubeadm join 192.168.xxx.xxx:6443 –token 46ok5q.cnv0yj8p1arec3is –discovery-token-ca-cert-hash sha256:0cae5db1df5fc4796147583f25750faeec420bd82fb8cb7b2b4121d4d4a0066e
6 部署容器网络
Calico是目前Kubernetes主流的网络方案。wget https://docs.projectcalico.org/manifests/calico.yaml,以下载yaml。需要修改字段CALICO_IPV4POOL_CIDR,与前面kubeadm init命令中的 –pod-network-cidr参数一样。
修改完后文件后
kubectl apply -f calico.yaml
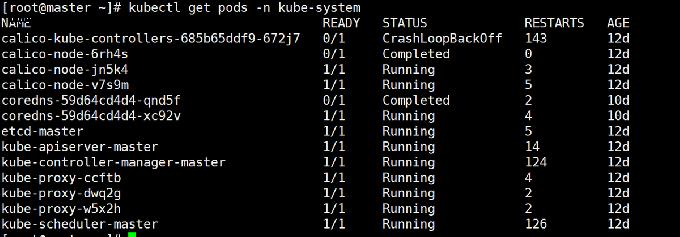
执行部署容器网络。稍等几分钟,然后执行kubectl get pods -n kube-system查看部署进度。等Calico Pod都Running,节点也会准备就绪。
7 查看kubernetes集群
查看集群信息
查看集群节点信息
8 部署控制台
Dashboard是官方提供的一个UI,可用于基本管理K8s资源,dashboard GitHub地址https://github.com/kubernetes/dashboard。如果GitHub访问较慢,可以参考我的另一篇文章GitHub 加速器(Watt Toolkit)
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.0/aio/deploy/recommended.yaml
默认Dashboard只能集群内部访问,vi recommended.yaml修改Service类型为NodePort,方便集群外的机器访问。
kind: ServiceapiVersion: v1metadata:labels:k8s-app: kubernetes-dashboardname: kubernetes-dashboardnamespace: kubernetes-dashboardspec:ports:- port: 443targetPort: 8443nodePort: 30443selector:k8s-app: kubernetes-dashboardtype: NodePortkubectl apply -f recommended.yamlkubectl get pods -n kubernetes-dashboard
待所有pod处于running的状态后,创建serviceaccount并绑定默认cluster-admin管理员集群角色:
# 创建用户kubectl create serviceaccount dashboard-admin -n kube-system# 用户授权kubectl create clusterrolebinding dashboard-admin –clusterrole=cluster-admin –serviceaccount=kube-system:dashboard-admin# 获取用户Tokenkubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk ‘/dashboard-admin/{print $1}’)
测试访问:https://192.168.xxx.xxx:30443,复制token后填入,进行登录。
9 部署问题
detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at
[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”. Please follow the guide at https://kubernetes.io/docs/setup/cri/
Docker的驱动程序cgroup,修改为systemd驱动,修改前 通过
docker info | grep cgrou
查看他的驱动信息(原来标红的是cgroupfs)
执行以下命令
vim /etc/docker/daemon.json{“exec-opts”:[“native.cgroupdriver=systemd”]}
重启后查看docker systemctl restart docker
The connection to the server localhost:8080 was refused – did you specify the right host or port?解决
- 原因:kubernetes master没有与本机绑定,集群初始化的时候没有绑定,此时设置在本机的环境变量即可解决问题。
- 解决:vim /etc/profile,在底部增加新的环境变量 export KUBECONFIG=/etc/kubernetes/admin.conf
- 最后执行source /etc/profile 让新增的环境变量生效。
各个节点执行kubectl –version且报错如下
Unable to connect to the server: net/http: TLS handshake timeout
但是只有master节点执行各种命令延迟较高,其他node节点正常,通过命令 free -m 发现主节点只有45M内存,意识到可能是给虚拟机的内存分小了(虚拟机分了2G),给虚拟机新增1G内存就解决了
# 重启kubelet服务systemctl daemon-reloadsystemctl restart kubelet
