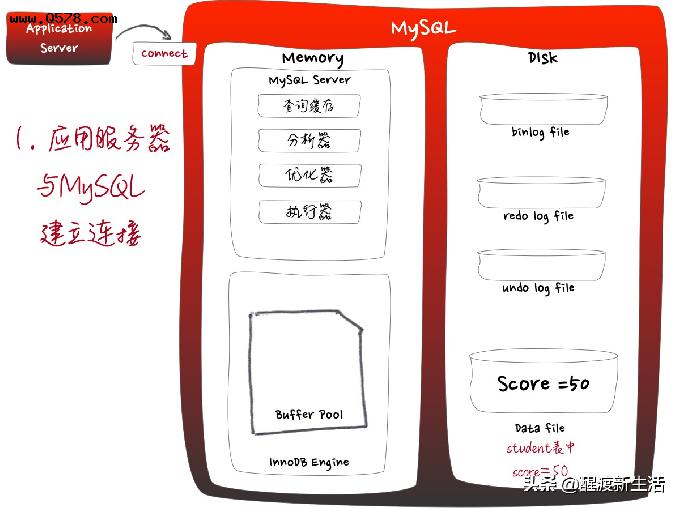
先看看一条SQL如何入库的
数据写入详细过程
为什么要拆分出两层架构
这是一条非常简单的SQL语句[update student set score=100 where score=50],从MySQL服务端接收SQL到写入磁盘,经过了Server层和InnoDB存储引擎,中间掺杂着磁盘读取、日志记录、内存更新、写入磁盘。
MySQL为什么将Server层和引擎层拆分?
- 由MySQL架构演变而来,进而实现「解耦」的效果
- 针对不同的场景,使用不同的存储引擎,灵活性更强
- MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力
MySQL主要包含2种存储引擎
- MyISAM(不支持事务,访问速度快)
- InnoDB(主流,支持事务)
郑重声明:本文内容及图片均整理自互联网,不代表本站立场,版权归原作者所有,如有侵权请联系管理员(admin#wlmqw.com)删除。
